28 KiB
28 KiB
基础环境配置
| 主机名 | IP地址 | 账号 | 密码 |
|---|---|---|---|
| Master | 自行设置 | Root | 自行设置 |
| Slave1 | 自行设置 | Root | 自行设置 |
| Slave2 | 自行设置 | Root | 自行设置 |
修改节点主机名
#Master
[root@localhost ~]# hostnamectl set-hostname master
[root@master ~]# bash
#Slave1
[root@localhost ~]# hostnamectl set-hostname slave1
[root@slave1 ~]# bash
#Slave2
[root@localhost ~]# hostnamectl set-hostname slave2
[root@slave2 ~]# bash
修改节点IP地址
#Master
[root@master ~]# nmcli conn show
NAME UUID TYPE DEVICE
eno16777736
[root@master ~]# nmcli conn modify "eno16777736" ipv4.method manual ipv4.addresses 10.0.0.100/24 ipv4.gateway 10.0.0.2 ipv4.dns 223.5.5.5 connect.autoconnect
#Slave1
[root@slave1 ~]# nmcli conn show
NAME UUID TYPE DEVICE
eno16777736
[root@slave1 ~]# nmcli conn modify "eno16777736" ipv4.method manual ipv4.addresses 10.0.0.101/24 ipv4.gateway 10.0.0.2 ipv4.dns 223.5.5.5 connect.autoconnect
#Slave2
[root@slave1 ~]# nmcli conn show
NAME UUID TYPE DEVICE
eno16777736
[root@slave2 ~]# nmcli conn modify "eno16777736" ipv4.method manual ipv4.addresses 10.0.0.102/24 ipv4.gateway 10.0.0.2 ipv4.dns 223.5.5.5 connect.autoconnect
#命令详解
nmcli conn show #网络连接详细信息
nmcli conn modify "eno16777736" #修改网卡eno16777736(此处为show出来的NAME)
ipv4.method manual #静态IP模式
ipv4.addresses #设置IP地址
ipv4.gateway #设置网关地址
ipv4.dns #设置DNS地址(非必写参数,比赛要求的话就写)
修改节点防火墙状态
#Master
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
#Slave1
[root@slave1 ~]# systemctl stop firewalld
[root@slave1 ~]# systemctl disable firewalld
#Slave2
[root@slave2 ~]# systemctl stop firewalld
[root@slave2 ~]# systemctl disable firewalld
#命令详解
stop #关闭防火墙
disable #禁止防火墙开机启动
修改节点SSH免密
#Master
[root@master ~]# ssh-keygen -t rsa
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id slave1
[root@master ~]# ssh-copy-id slave2
#Slave1
[root@slave1 ~]# ssh-keygen -t rsa
[root@slave1 ~]# ssh-copy-id master
[root@slave1 ~]# ssh-copy-id slave2
#Slave2
[root@slave2 ~]# ssh-keygen -t rsa
[root@slave2 ~]# ssh-copy-id master
[root@slave2 ~]# ssh-copy-id slave1
#此处自行输入密码
#命令详解
ssh-keygen -t rsa #生成密钥对
ssh-copy-id #复制密钥
修改节点的IP地址与主机名映射关系
#Master
[root@master ~]# vi /etc/hosts
10.0.0.100 master
10.0.0.101 slave1
10.0.0.102 slave2
[root@master ~]# scp /etc/hosts slave1:/etc/
[root@master ~]# scp /etc/hosts slave1:/etc/
#此处自行输入密码
#命令详解
scp命令
语法:scp 路径 目标主机:目标路径
Hadoop集群部署
2.1 JDK的部署与安装
#Master
[root@master ~]# mkdir /opt/module
[root@master opt]# cd /opt/
[root@master opt]# ls
module softwares
[root@master opt]# cd /opt/softwares/
[root@master softwares]# tar -zxvf jdk-8u401-linux-x64.tar.gz -C /opt/module/
[root@master softwares]# cd /opt/module/
[root@master module]# ls
jdk1.8.0_401
[root@master module]# mv jdk1.8.0_401 jdk
#修改环境变量(末尾添加)
[root@master module]# vi /etc/profile
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH="$JAVA_HOME/bin:$PATH"
#环境变量生效
[root@master module]# source /etc/profile
#查看Java版本
[root@master module]# java -version
java version "1.8.0_401"
Java(TM) SE Runtime Environment (build 1.8.0_401-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.401-b10, mixed mode)
#节点创建module路径
#Slave1
[root@slave1 ~]# mkdir /opt/module
#Slave2
[root@slave2 ~]# mkdir /opt/module
#拷贝jdk
#Master
[root@master ~]# scp -r /opt/module/jdk/ slave1:/opt/module/jdk
[root@master ~]# scp -r /opt/module/jdk/ slave2:/opt/module/jdk
#拷贝环境变量
#Master
[root@master module]# scp /etc/profile slave1:/etc/
profile
[root@master module]# scp /etc/profile slave2:/etc/
profile
#测试
#Slave1
[root@slave1 ~]# source /etc/profile
[root@slave1 ~]# java -version
#Slave2
[root@slave2 ~]# source /etc/profile
[root@slave2 ~]# java -version
#命令详解
mkdir #创建目录
语法:mkdir 目录名
cd #进入目录
语法:cd 目录名
tar #解压缩/压缩
语法:tar -参数 -C 指定目录(不使用-C默认当前目录)
ls #列出目录下文件
语法:ls 目录
mv #移动/重命名
语法:mv 源文件 新文件
2.1 Hadoop集群配置
#Master
[root@master softwares]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
[root@master softwares]# mv hadoop-3.1.3/ hadoop
[root@master module]# vi /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH="$HADOOP_HOME/bin:$PATH"
[root@master module]# source /etc/profile
[root@master module]# hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
#Hadoop相关配置文件
[root@master module]# cd hadoop/
[root@master hadoop]# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
</configuration>
[root@master hadoop]# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
[root@master hadoop]# vi etc/hadoop/yarn-site.xml
<configuration>
<!--Site specific YARN configuration properties-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
[root@master hadoop]# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
[root@master hadoop]# vi etc/hadoop/workers
master
slave1
slave2
[root@master hadoop]# vi etc/hadoop/hadoop-env.sh
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk
[root@master hadoop]# vi etc/hadoop/yarn-env.sh
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk
[root@master hadoop]# vi /etc/profile
# HADOOP_USER
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
[root@master hadoop]# source /etc/profile
[root@master hadoop]# scp -r /opt/module/hadoop/ slave1:/opt/module/hadoop/
[root@master hadoop]# scp -r /opt/module/hadoop/ slave2:/opt/module/hadoop/
[root@master module]# scp /etc/profile slave1:/etc/
[root@master module]# scp /etc/profile slave2:/etc/
#Slave1
[root@slave1 ~]# source /etc/profile
#Slave2
[root@slave2 ~]# source /etc/profile
#初始化Hadoop
[root@master hadoop]# hdfs namenode -format
#Hadoop参数配置详解
https://blog.51cto.com/u_14844/7277649
Hadoop初始化正确样式
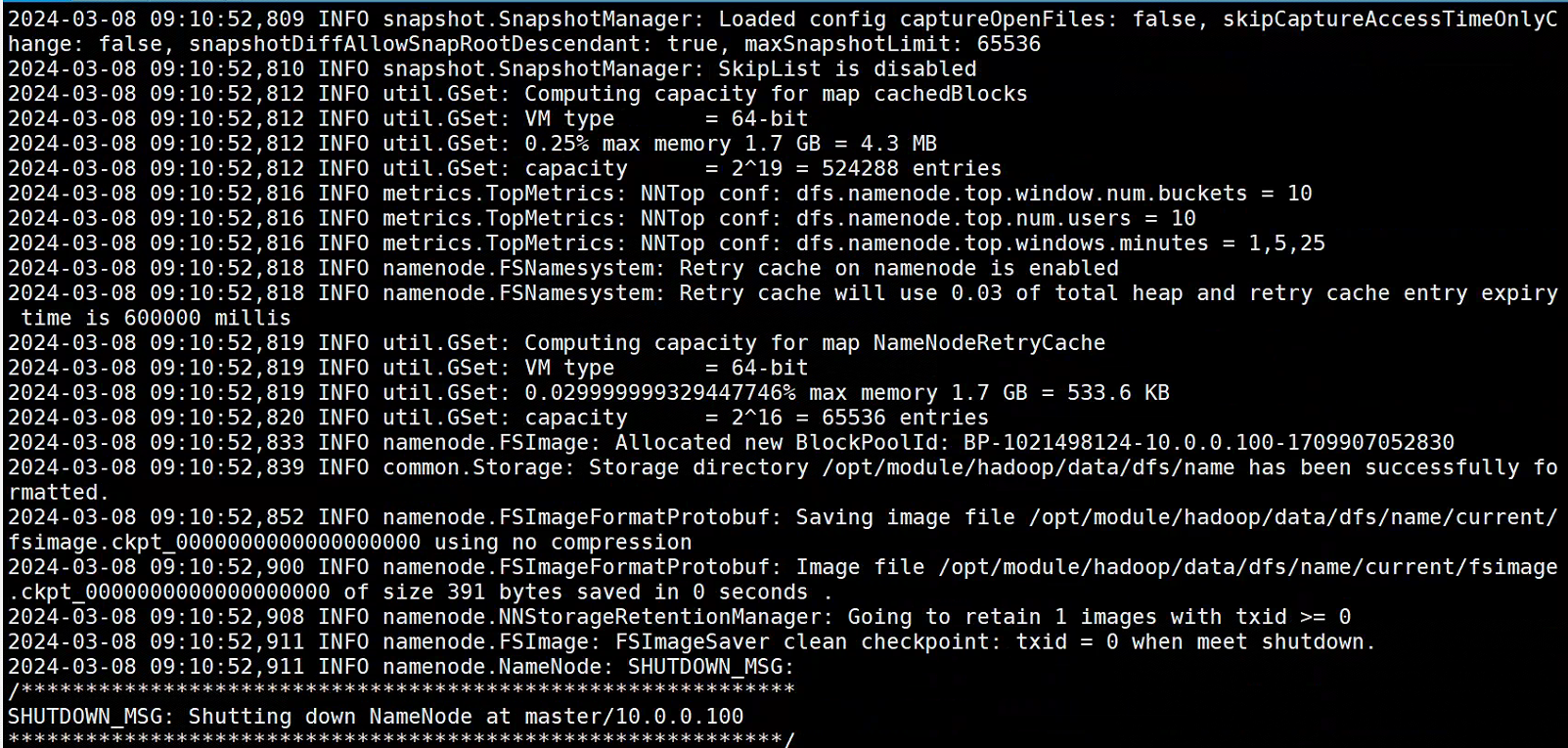
#Master
# 启动Hadoop集群
[root@master hadoop]# ./sbin/start-all.sh
Hadoop正确启动样式
#Master

#Slave1

#Slave2

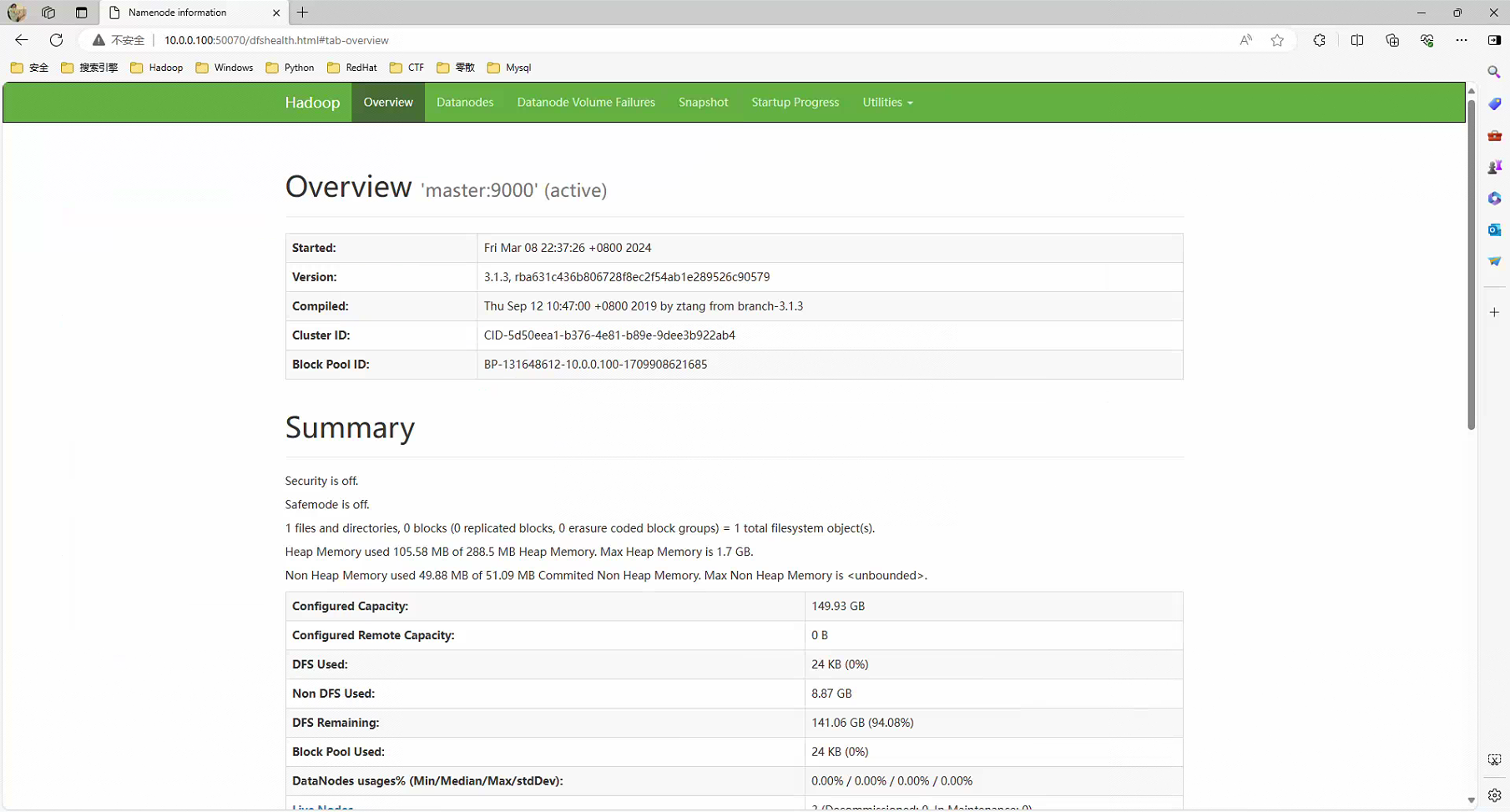
#验证
Windows访问Web
Hive组件部署
3.1 Mysql数据库部署
#Master
#卸载系统自带Mariadb(避免冲突)
[root@master hadoop]# rpm -qa | grep mariadb
mariadb-libs-5.5.44-2.el7.centos.x86_64
[root@master hadoop]# rpm -e --nodeps mariadb-libs
#安装Mysql(通过rpm进行安装,必须按照顺序进行)
[root@master softwares]# cd Mysql/
[root@master Mysql]# rpm -ivh mysql-community-common-5.7.16-1.el7.x86_64.rpm
[root@master Mysql]# rpm -ivh mysql-community-libs-5.7.16-1.el7.x86_64.rpm
[root@master Mysql]# rpm -ivh mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
[root@master Mysql]# rpm -ivh mysql-community-client-5.7.16-1.el7.x86_64.rpm
[root@master Mysql]# rpm -ivh mysql-community-server-5.7.16-1.el7.x86_64.rpm --nodeps --force
#查看是否安装成功
[root@master Mysql]# rpm -qa | grep mysql
mysql-community-libs-5.7.16-1.el7.x86_64
mysql-community-client-5.7.16-1.el7.x86_64
mysql-community-common-5.7.16-1.el7.x86_64
mysql-community-libs-compat-5.7.16-1.el7.x86_64
mysql-community-server-5.7.16-1.el7.x86_64
#启动Mysql服务
[root@master Mysql]# service mysqld start
#查看Mysql临时密码并登录
[root@master Mysql]# grep 'temporary password' /var/log/mysqld.log
2024-03-08T14:47:30.088527Z 1 [Note] A temporary password is generated for root@localhost: RwwuuuITi6_g
[root@master Mysql]# mysql -uroot -p'RwwuuuITi6_g'
#配置Mysql
#修改密码策略的验证级别为0
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)
#修改密码长度验证最低为1
mysql> set global validate_password_length=1;
Query OK, 0 rows affected (0.00 sec)
#修改密码
mysql> alter user 'root'@'localhost' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
#修改root权限
mysql> grant all privileges on *.* to 'root'@'%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)
#刷新权限表
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
#自行测试登陆密码是否正常
3.2 Hive部署
#Master
#解压缩并重命名
[root@master softwares]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
[root@master module]# mv apache-hive-3.1.2-bin/ hive
#修改环境变量并生效
[root@master module]# vi /etc/profile
export HIVE_HOME=/opt/module/hive
export PATH="$HIVE_HOME/bin:$PATH"
[root@master module]# source /etc/profile
#拷贝jdbc驱动到hive的lib目录下
[root@master module]# cp /opt/softwares/Mysql/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
#修改配置文件
[root@master module]# vi hive/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver </value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456 </value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
#初始化元数据库,创建Hive元数据库
[root@master module]# mysql -uroot -p
mysql> create database metastore;
Query OK, 1 row affected (0.00 sec)
mysql> quit;
Bye
#替换版本冲突jar包(否则初始化Hive有可能失败)
[root@master module]# cp hadoop/share/hadoop/common/lib/guava-27.0-jre.jar hive/lib/
参考链接:https://www.cnblogs.com/lfri/p/13096283.html
#Hive参数详解
参考链接:https://blog.csdn.net/wang2leee/article/details/134151868
#初始化成功图片
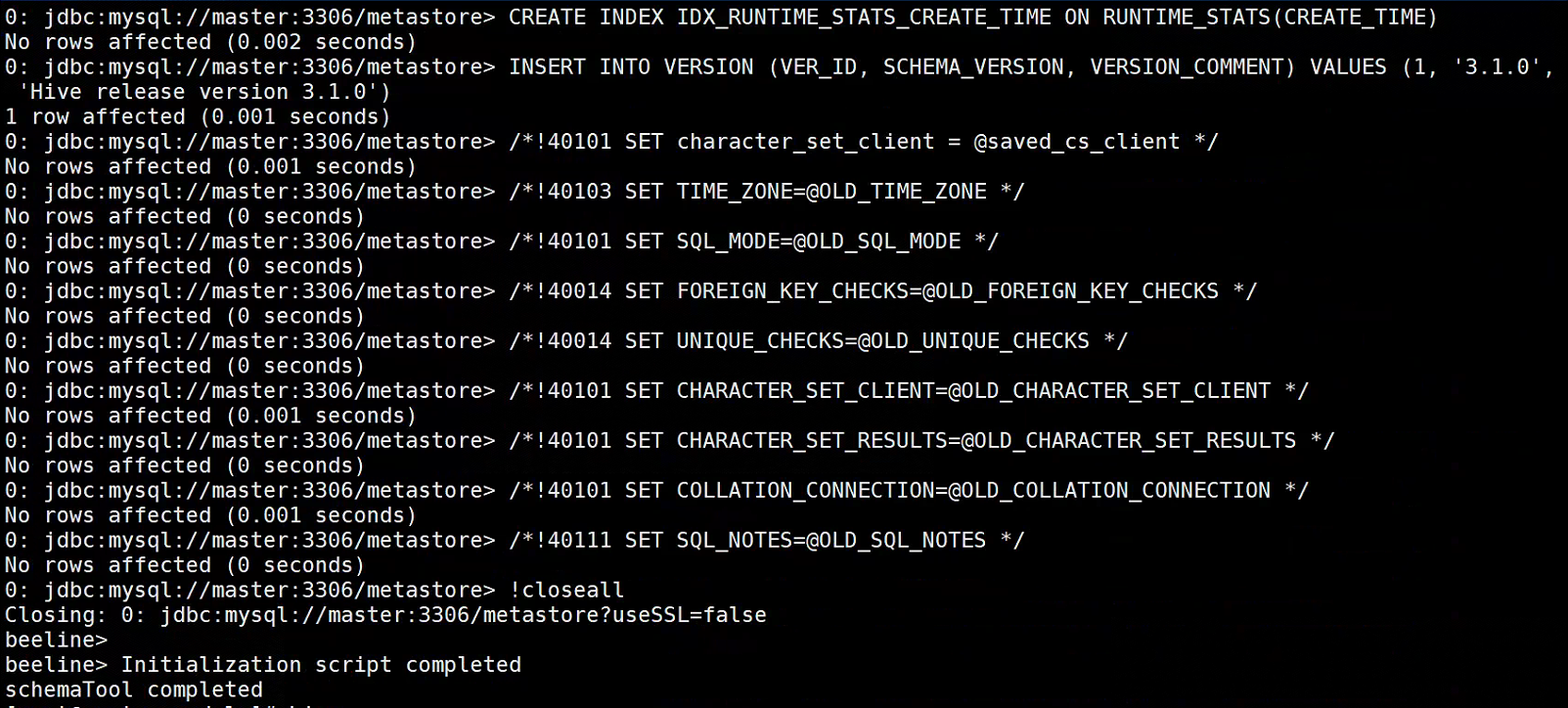
#启动及测试Hive
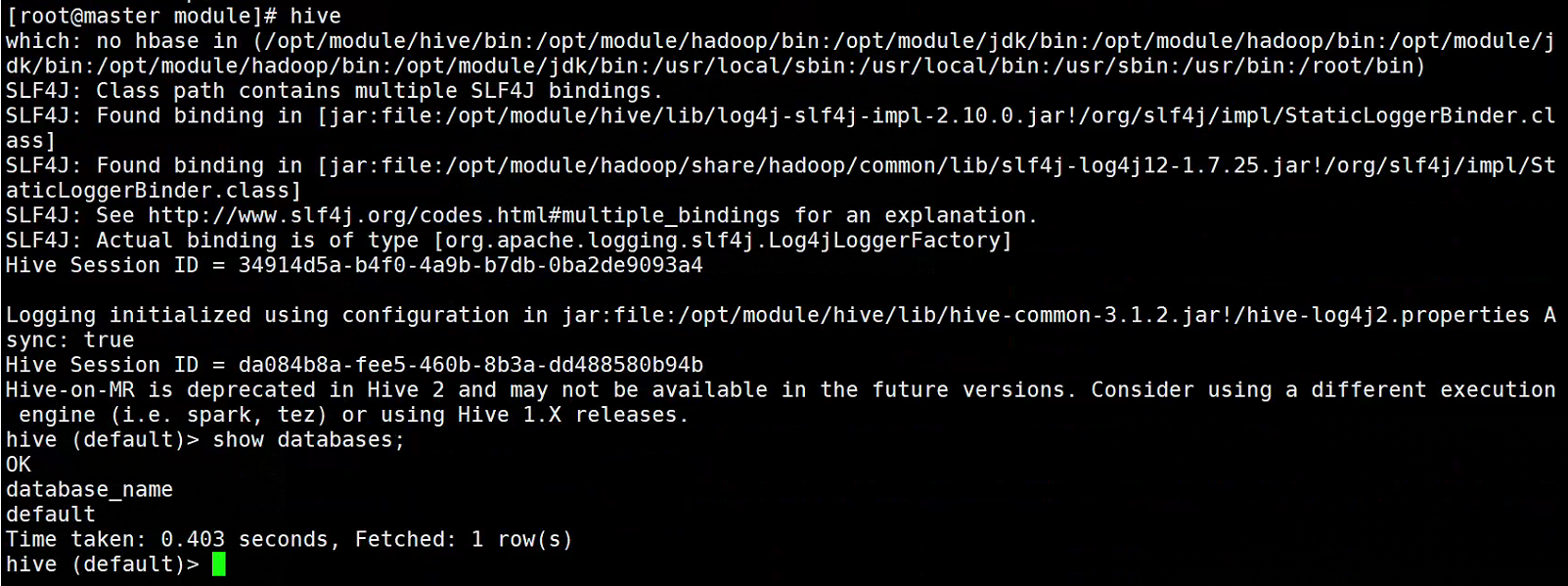
Spark组件部署
#Master
[root@master module]# tar -zxvf /opt/softwares/spark-3.1.3-bin-hadoop3.2.tgz -C /opt/module/
[root@master module]# mv spark-3.1.3-bin-hadoop3.2/ spark
[root@master module]# vi /etc/profile
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH="$SPARK_HOME/bin:$PATH"
[root@master module]# source /etc/profile
[root@master module]# cd spark/conf/
[root@master conf]# ls
[root@master conf]# mv workers.template workers
[root@master conf]# vi workers
master
slave1
slave2
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
export JAVA_HOME=/opt/module/jdk
export HADOOP_HOME=/opt/module/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
export SPARK_YARN_USER_ENV="CLASSPATH=/opt/module/hadoop/etc/hadoop"
export YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
[root@master conf]# scp -r /opt/module/spark/ slave1:/opt/module/
[root@master conf]# scp -r /opt/module/spark/ slave2:/opt/module/
[root@master conf]# /opt/module/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
#自行通过jps查看节点是否包含Worker即可
#Spark详解
参考链接:https://zhuanlan.zhihu.com/p/99398378
#Spark测试
[root@master spark]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.12-3.1.3.jar
#正确图示
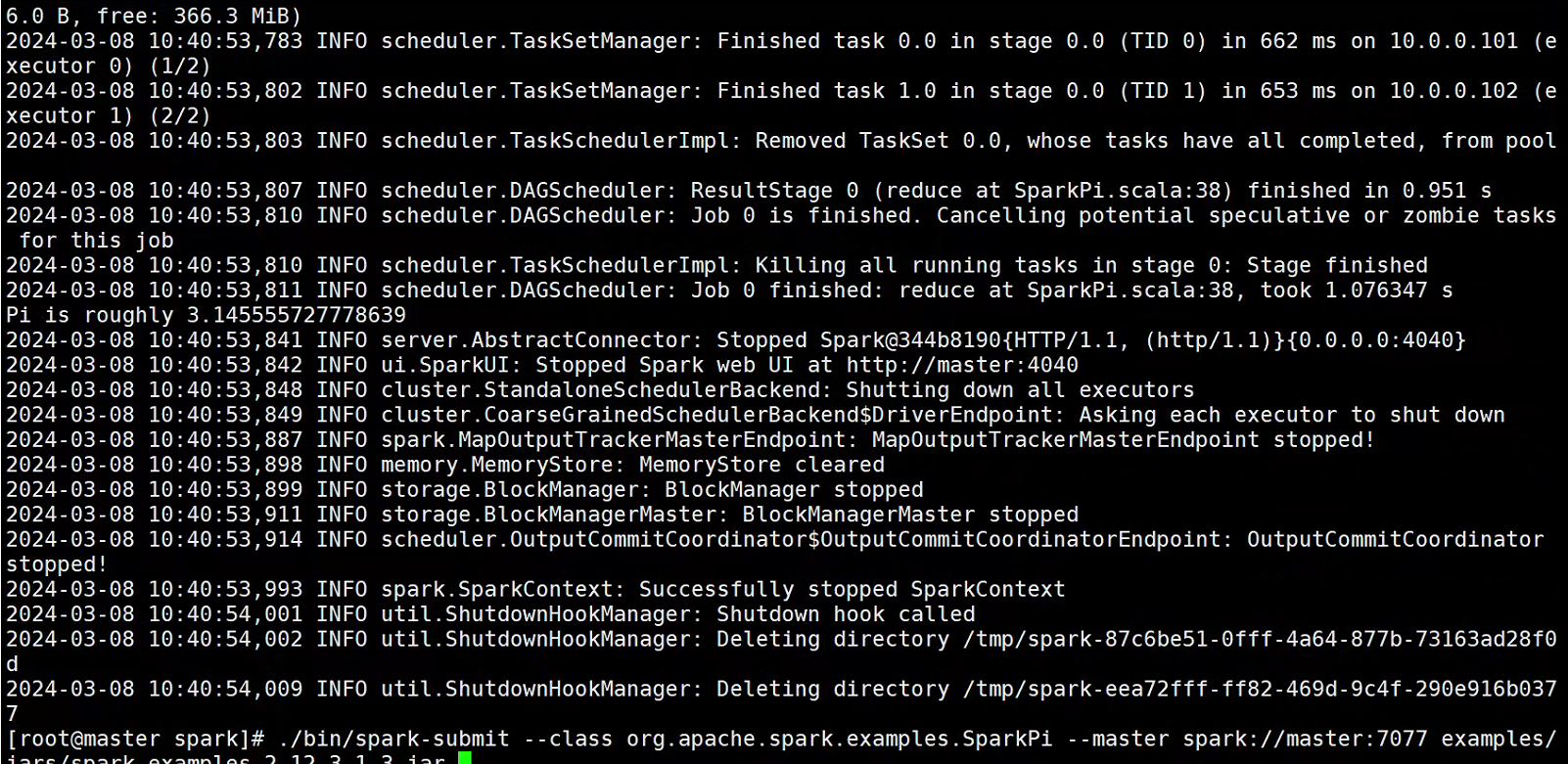
#Windows访问SparkWeb
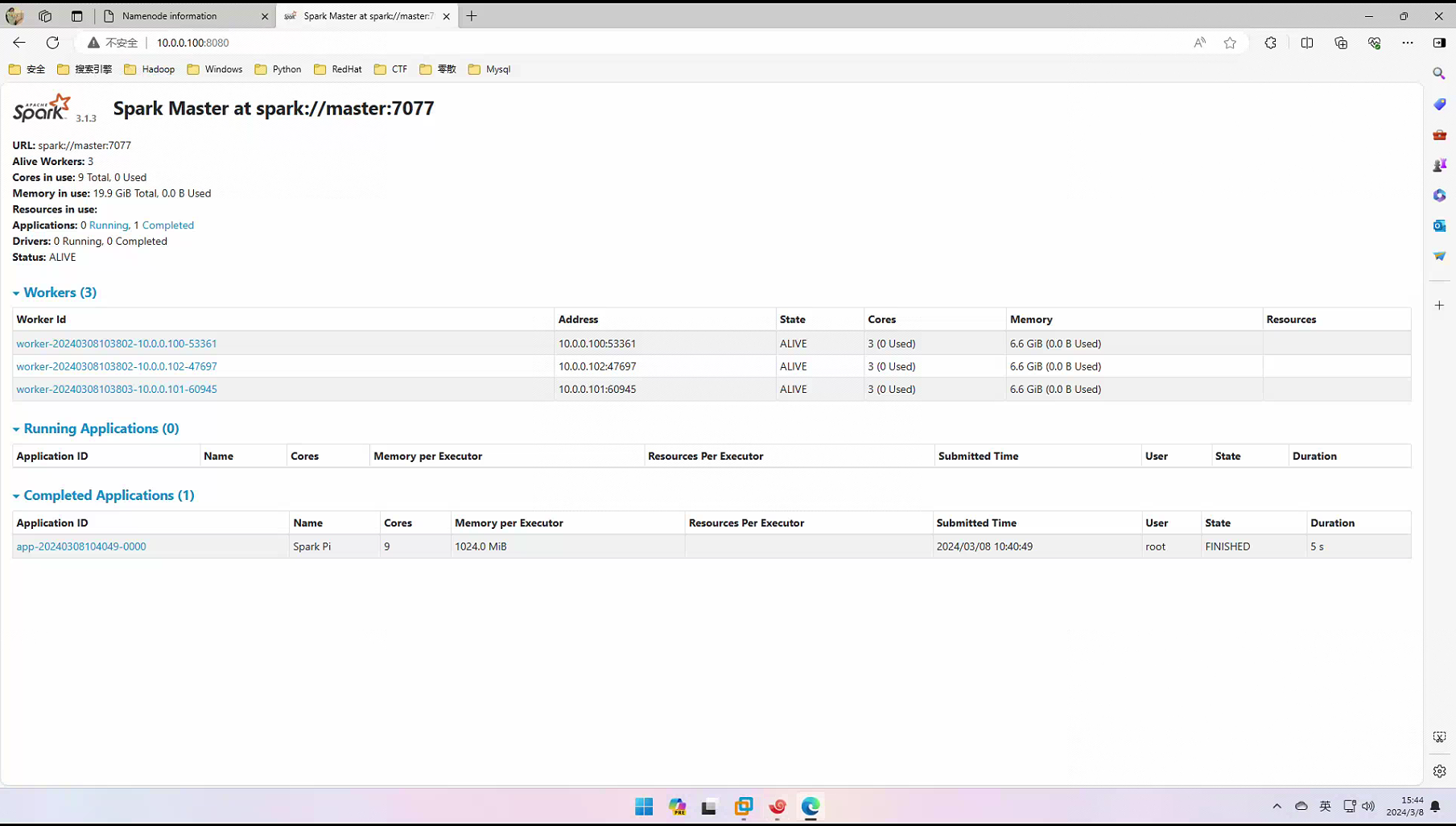
Flink组件部署
#Master
[root@master flink]# tar -zxvf /opt/softwares/flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/
[root@master flink]# mv /opt/module/flink-1.14.0 /opt/module/flink
[root@master flink]# vi /etc/profile
# FLINK_HOME
export FLINK_HOME=/opt/module/flink
export PATH="$FLINK_HOME/bin:$PATH"
[root@master flink]# source /etc/profile
[root@master flink]# vim conf/flink-conf.yaml
jobmanager.rpc.address: master
[root@master flink]# vi workers
master
slave1
slave2
[root@master conf]# scp -r /opt/module/flink/ slave1:/opt/module/flink
[root@master conf]# scp -r /opt/module/flink/ slave2:/opt/module/flink
[root@master flink]# ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host master.
Starting taskexecutor daemon on host slave1.
Starting taskexecutor daemon on host slave2.
#自行通过jps查看进程(TaskManagerRunner)
#测试(测试之前关闭Spark集群)
[root@master flink]# flink run -m master:8081 /opt/module/flink/examples/batch/WordCount.jar
#FLink详解
Flink概念
参考链接:https://blog.csdn.net/qq_35423154/article/details/113759891
配置参数解析
参考链接:https://zhuanlan.zhihu.com/p/58795683
#测试成功图片(Windows访问Web端)
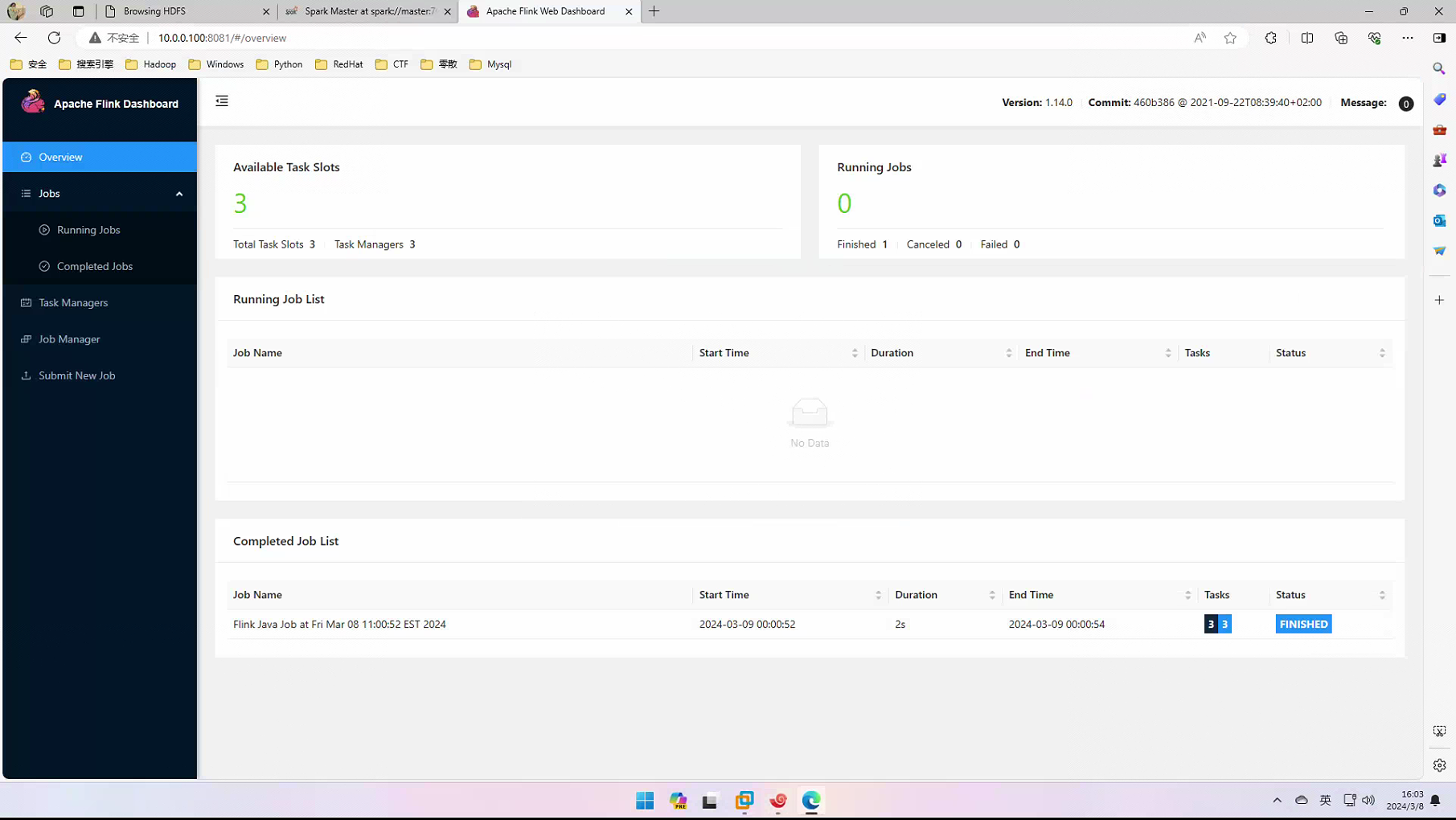
Flume组件部署
[root@master spark]# tar -zxvf /opt/softwares/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
[root@master spark]# mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
[root@master flume]# vi /etc/profile
# FLUME_HOME
export FLUME_HOME=/opt/module/flume
export PATH="$FLUME_HOME/bin:$PATH"
[root@master flume]# source /etc/profile
[root@master flume]# rm -rf /opt/module/flume/lib/guava-11.0.2.jar
[root@master flume]# vi /opt/module/flume/conf/log4j.properties
flume.log.dir=/opt/module/flume/logs
# 测试
[root@master flume]# mkdir job
[root@master flume]# cd job
[root@master job]# vi flume-netcat-logger.conf
# name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[root@master flume]# ./bin/flume-ng agent --conf conf --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.loogger=INFO,console
#正确图示
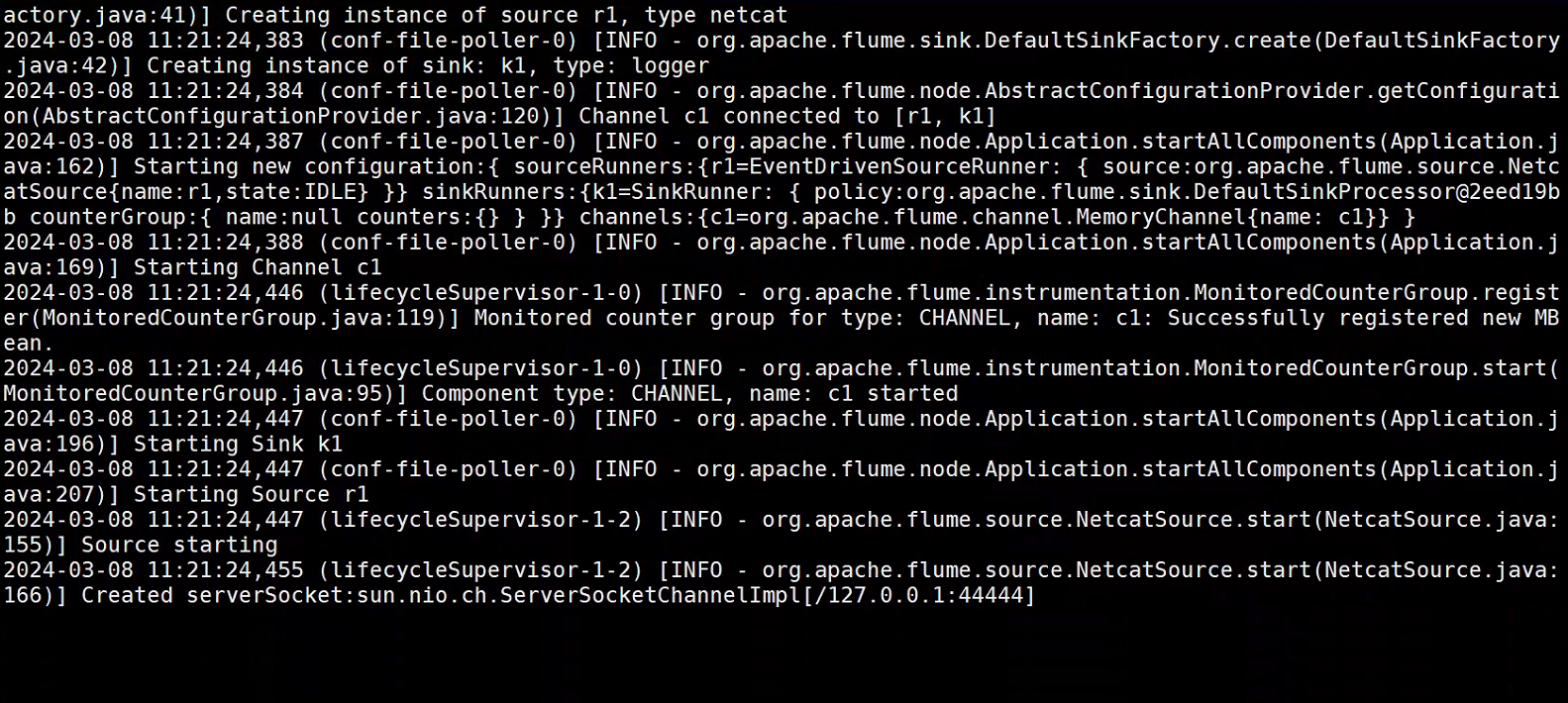
#Master机器,再开一个连接页面,使用nc(没有的话需要自行安装)
**需要配置Yum源才能用,具体自行百度
yum -y install nc

#再查看Flume会话(接受到NC监听端口会话Flume正常)
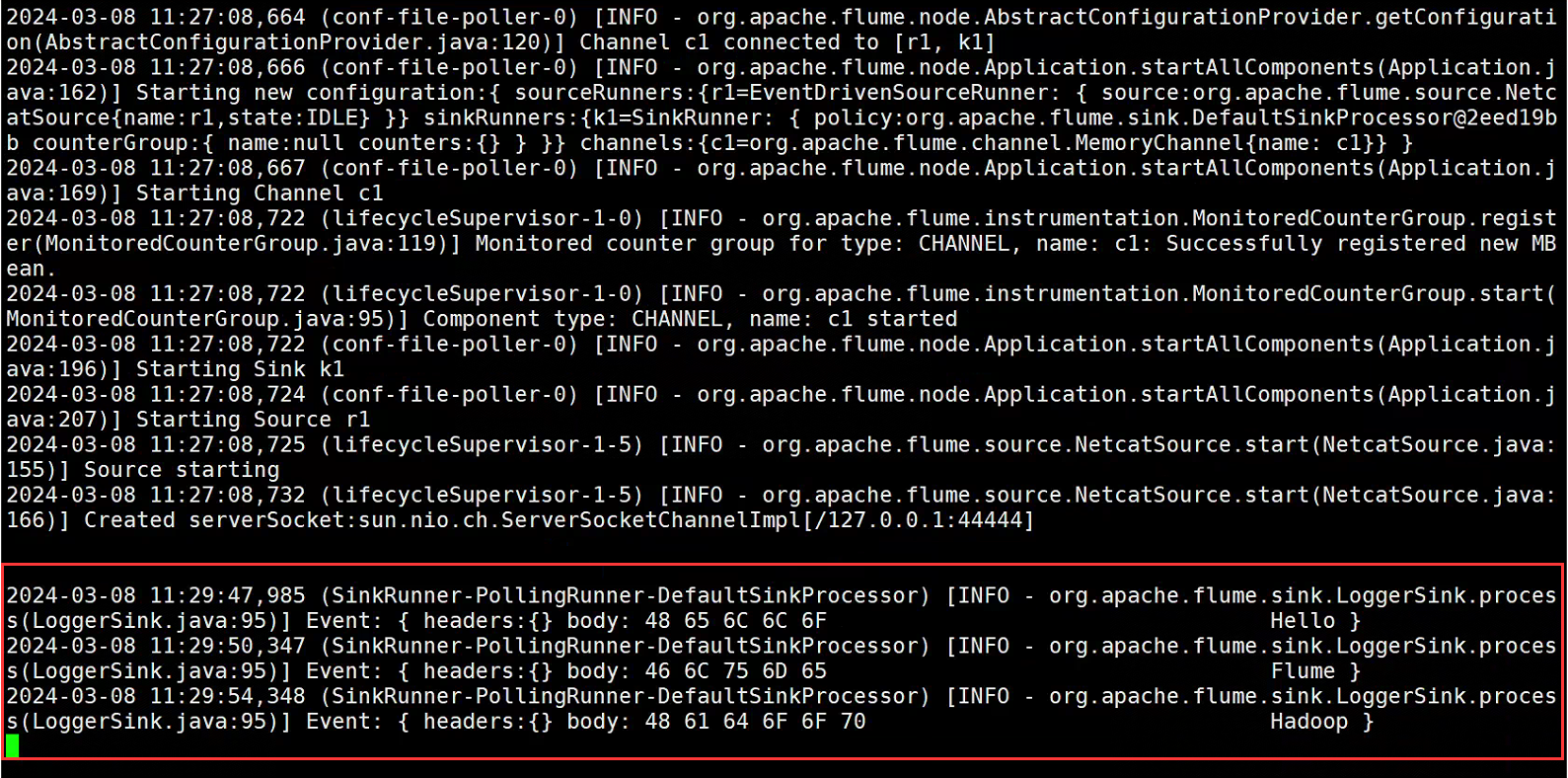
Zoopeeper组件部署
[root@master module]# tar -zxvf /opt/softwares/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
[root@master module]# mv /opt/module/apache-zookeeper-3.5.7-bin /opt/module/zookeeper
[root@master module]# vi /etc/profile
# ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH="$ZOOKEEPER_HOME/bin:$PATH"
[root@master module]# source /etc/profile
#配置服务器编号
[root@master module]# cd zookeeper/
[root@master zookeeper]# mkdir zkData
[root@master zookeeper]# cd zkData/
[root@master zkData]# vi myid
2
[root@master conf]# mv zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
dataDir=/opt/module/zookeeper/zkData
server.2=master:2888:3888
server.3=slave1:2888:3888
server.4=slave2:2888:3888
[root@master conf]# scp -r /opt/module/zookeeper slave1:/opt/module/
[root@master conf]# scp -r /opt/module/zookeeper slave2:/opt/module/
#Slave1
[root@slave1 zkData]# vi myid
3
#Slave2
[root@slave2 zkData]# vi myid
4
#启动集群
[root@master conf]# /opt/module/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave1 module]# /opt/module/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave2 module]# /opt/module/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#各个节点使用/opt/module/zookeeper/bin/zkServer.sh status自行查看进程状态
KafKa组件部署
[root@master module]# tar -zxvf /opt/softwares/kafka_2.12-2.4.0.tgz -C /opt/module/
[root@master module]# mv /opt/module/kafka_2.12-2.4.0 /opt/module/kafka
[root@master module]# vi /etc/profile
# KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH="$KAFKA_HOME/bin:$PATH"
[root@master module]# source /etc/profile
[root@master module]# vi /opt/module/kafka/config/server.properties
# 唯⼀值
broker.id=0
# kafka启动会⾃动创建
log.dirs=/opt/module/kafka/logs
# zk连接
zookeeper.connect=master:2181,slave1:2181,slave2:2181/kafka
[root@master module]# scp -r /opt/module/kafka slave1:/opt/module/
[root@master module]# scp -r /opt/module/kafka slave2:/opt/module/
#修改节点的broker.id值
[root@slave1 module]# vim /opt/module/kafka/config/server.properties
broker.id=1
[root@slave2 hadoop]# vim /opt/module/kafka/config/server.properties
broker.id=2
#各个节点启动Kafka
[root@master module]# /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[root@slave1 module]# /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
[root@slave2 module]# /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
#测试
自行使用jps查看节点进程(Kafka)
MaxWell组件部署
[root@master module]# tar -zxvf /opt/softwares/maxwell-1.29.2.tar.gz -C /opt/module/
[root@master module]# mv /opt/module/maxwell-1.29.2 /opt/module/maxwell
[root@master module]# vi /etc/profile
# MAXWELL_HOME
export MAXWELL_HOME=/opt/module/maxwell
export PATH="$MAXWELL_HOME/bin:$PATH"
[root@master module]# source /etc/profile
[root@master module]# vi /etc/my.cnf
server-id = 1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=ds_pub
[root@master module]# mysql -uroot -p'123456'
mysql> create database ds_pub;
Query OK, 1 row affected (0.01 sec)
mysql> CREATE DATABASE maxwell;
Query OK, 1 row affected (0.00 sec)
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_length=4;
Query OK, 0 rows affected (0.00 sec)
#创建一个maxwell用户,在任何主机上都可以访问
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
Query OK, 0 rows affected (0.00 sec)
#授予maxwell在maxwell数据库所有权限
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
Query OK, 0 rows affected (0.00 sec)
#授予maxwell用户数据库和表的select权限以及复制权限
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
Bye
Redis组件部署
[root@master module]# tar -zxvf /opt/softwares/redis-6.2.6.tar.gz -C /opt/module/
[root@master module]# mv /opt/module/redis-6.2.6 /opt/module/redis
#查看gcc编译器版本(自行安装使用yum或者离线都可以)
[root@master module]# gcc --version
gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
[root@master module]# cd redis/
[root@master redis]# make
[root@master redis]# make install
[root@master redis]# cp redis.conf /root/
[root@master redis]# cd
[root@master ~]# vi redis.conf
bind 10.0.0.100 -::1
#设置在后台启动
daemonize yes
#此处如果提示redis-server找不到命令,直接在/etc/profile添加环境变量也可以
[root@master module]# vi /etc/profile
# REDIS_HOME
export REDIS_HOME=/opt/module/redis
export PATH="$REDIS_HOME/src:$PATH"
[root@master ~]# redis-server my_redis.conf
[root@master ~]# redis-cli -h 10.0.0.100 -p 6379
10.0.0.100:6379> exit
Hbase组件部署
[root@master module]# tar -zxvf /opt/softwares/hbase-2.2.2-bin.tar.gz -C /opt/module/
[root@master module]# mv hbase-2.2.2 hbase
[root@master module]# vi hbase/conf/hbase-env.sh
export JAVA_HOME=/opt/module/jdk
#禁用Hbase自带的Zookeeper,使用外部独立的Zookeeper
export HBASE_MANAGES_ZK=false
[root@master module]# vi hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
# zkData需要手动创建
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/hbase/zkData</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
[root@master module]# vi hbase/conf/regionservers
master
slave1
slave2
[root@master module]# hbase/bin/start-base.sh
#自行使用jps查看进程(HMaster,HRegionServer,HQuorumPeer)
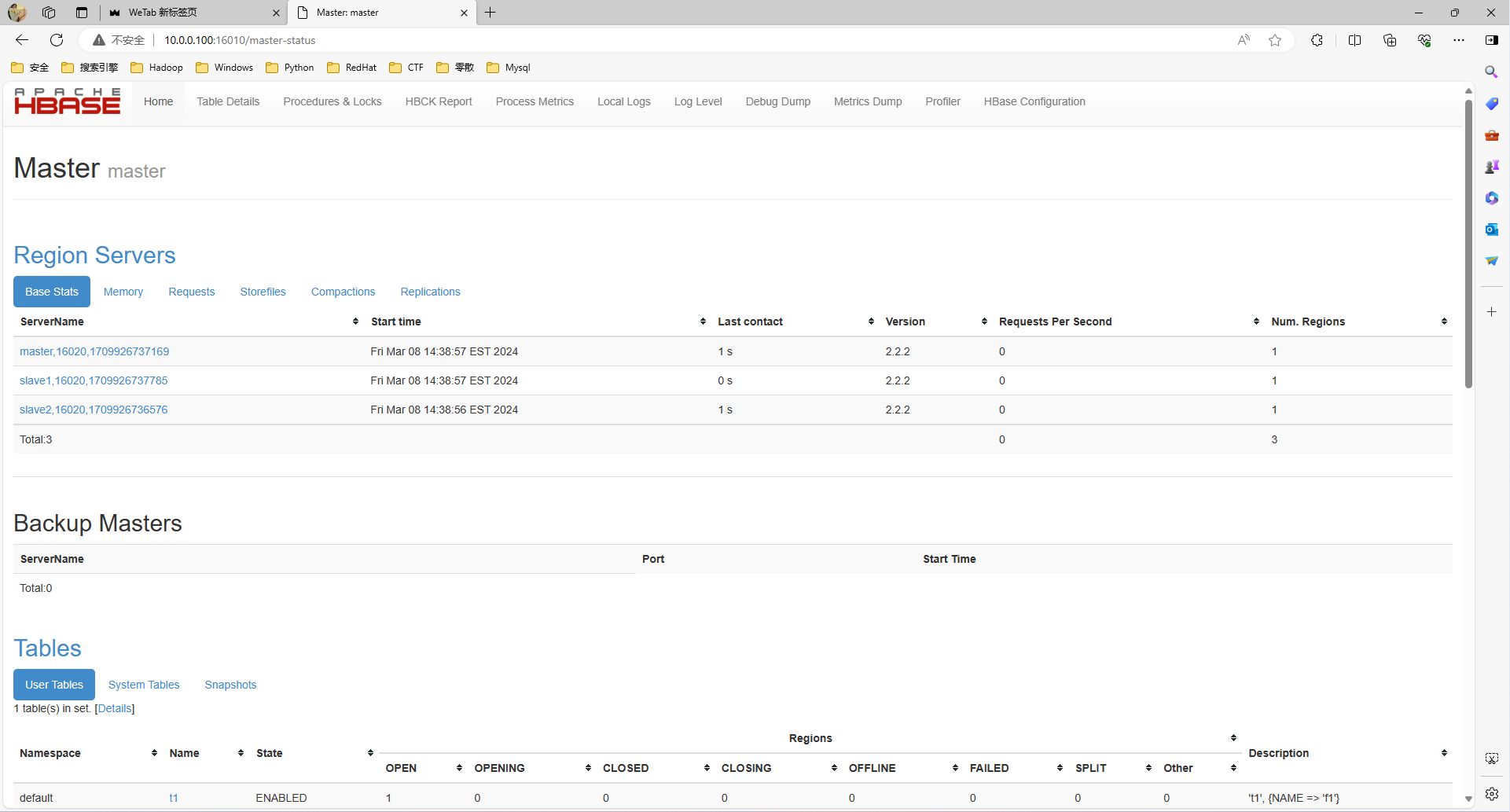
#测试
[root@master hbase]# ./bin/hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.2, re6513a76c91cceda95dad7af246ac81d46fa2589, Sat Oct 19 10:10:12 UTC 2019
Took 0.0025 seconds
#创建表
hbase(main):001:0> create 't1','f1'
Created table t1
Took 2.5555 seconds
=> Hbase::Table - t1
hbase(main):002:0>
#如果启动发现没有HQuorumPeer进程,查看Hbase日志
[root@master logs]# cat hbase-root-master-master.log | grep 2181
#发现有连接到Master,Slave1,Slave2的Zookeeper端口就可以
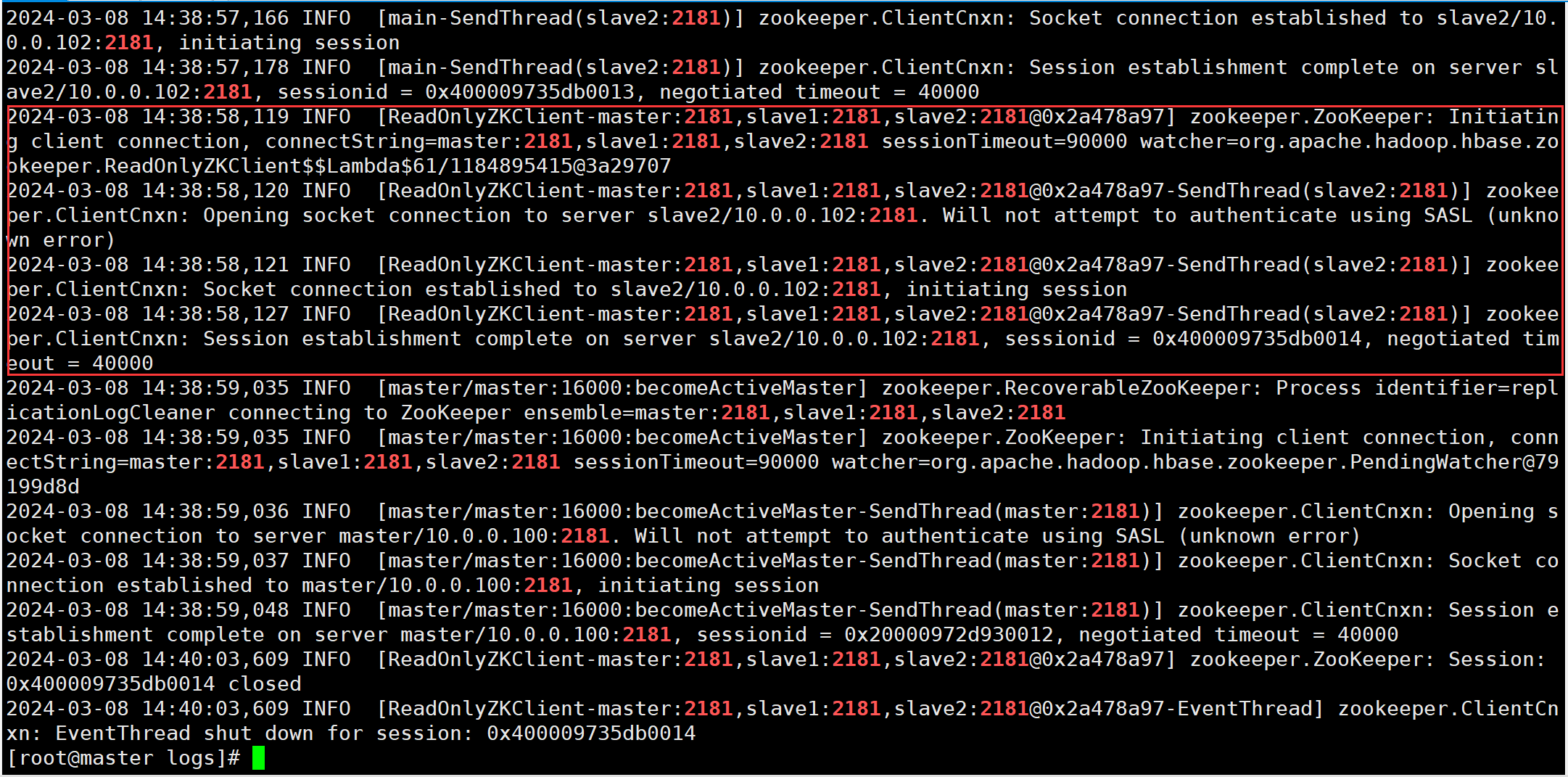
#Windows中Web访问测试